推土机驶来!AMD顶级FX处理器深度评测
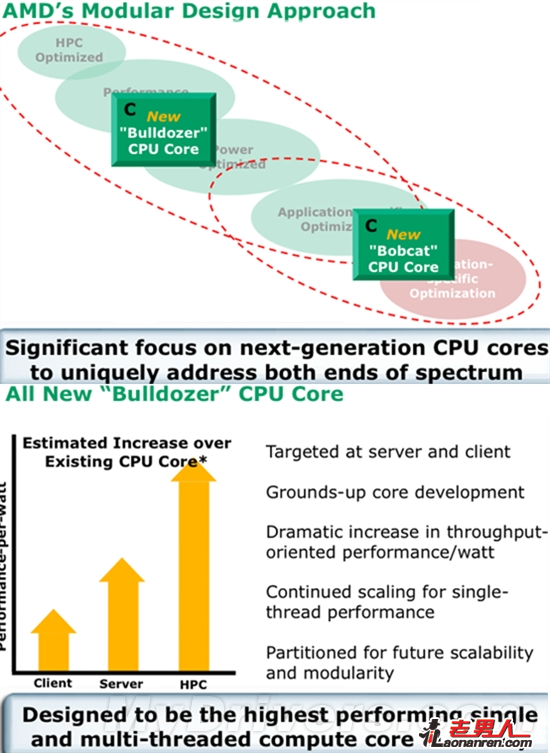
如果将时钟往回拨四年,彼时处理器江湖中的AMD还在依靠65nm K8打天下,45nm K10正在发布前的最后时刻,Intel Tick-Tock战略则才刚刚开始实施,人们更为津津乐道的还是Intel那盘美味的“扣肉”。2007年7月底,AMD提出了两个不同的全新处理器架构,其一是低功耗的、已用于Fusion APU的“山猫”(Bobcat),其二就是高性能的“推土机”(Bulldozer)。
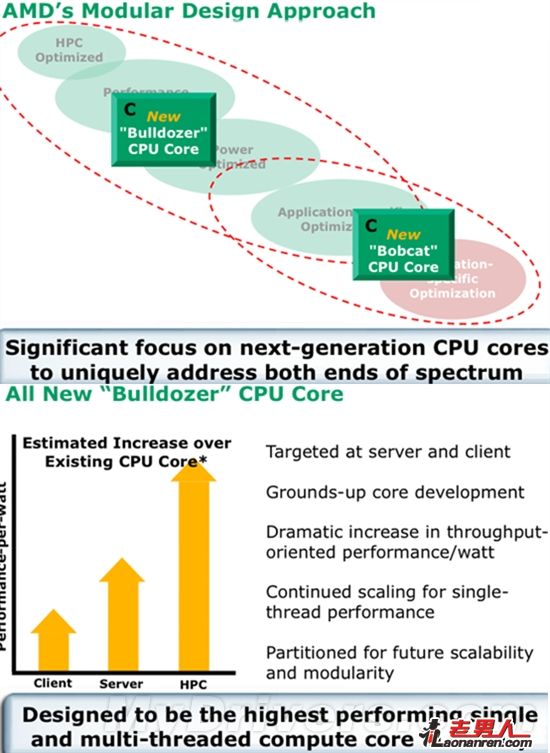
推土机不同于K10的小步慢跑,而是会从根本上改变AMD处理器的底层架构设计,简单地说就是变为模块化。AMD宣称推土机相比K10可在每瓦特性能上提升30-100%,会成为“有史以来最高性能的单线程和多线程计算核心”。按照规划,推土机将在2009年上半年诞生,对抗Intel计划于2008年底发布的新一代Nehalem。
谁曾想到,结果这一等就是四年半。“扣肉”下桌了,Nehalem来了又走了,Westmere来了又走了,Sandy Bridge来了也快走了,Ivy Bridge都不远了,推土机才终于在满天的流言蜚语中开了出来。2011年10月12号,AMD终于发布这款号称革命性的产品,并命名为FX系列。
为了显示自己的高端地位,AMD在推土机上重新祭出了消失多年的“FX”品牌。在六七年前,AMD正是凭借Athlon 64 FX系列和Intel在顶级处理器领域展开了一场殊死搏斗,双方甚至都不惜把双路服务器系统搬到桌面上来。FX的重出江湖一方面意味着AMD品牌策略的变化,从龙系列改为更简单明了的公司名加字母序列,另一方面也表明了AMD在这款新品上的信心和决心。

即便如此,推土机FX系列处理器的市场定位并不高,最高端型号FX-8150的官方标价也仅有245美元,大大低于Core i7-2600K的317美元,更接近于216美元的Core i5-2500K。这下一来就有趣了:AMD在处理器和显卡两条线上都没有去争夺性能制高点,而是通过田忌赛马策略攻击竞争对手的主流级别产品,大打性价比王牌。也许这看起来有些“不争气”,但对于AMD来说无疑是最为实际的,从消费者的角度来说也能让更多主流消费者以更低的价格买到更高性能的产品,何乐而不为呢?

说一千道一万,漫长的等待现在总算是结束了,是骡子是马也该拉出来遛遛了,不过因为在评测过程中碰到了前所未有的意外,不幸一直拖延到现在才完成,这里也向各位热心的读者致歉。
本次评测我们陆续拿到了三颗顶级八核心FX-8150和一颗六核心FX-6100,以及三块配套的华硕玩家国度主板Crosshair V Formula,还有一套水冷套装,在国内绝对是最全面的,而参与对比的是Core i5-2500K、Core i5-2300。这里我们会尽可能地做出全面细致的评测解析,而且后续还会有其它一些补充项目,比如对比现在的旗舰六核心Phenom II X6 1100T情况如何?推土机放在8系列主板上是否会有损失?Eyefinity三屏环境下游戏能跑多快?


推土机模块化架构
有关推土机的架构细节之前我们已经陆陆续续做过非常全面的介绍,不过这毕竟是AMD的多年心血和推土机的核心精髓所在,因此这里我们再从高级层面(不涉及底层半导体设计)归纳总结一下。
按照AMD的设计理念,推土机架构要在多线程应用中提供性能、成本和功耗的平衡,并专注于高频率、资源共享,以实现在下一代应用环境中的最佳吞吐、最快速度。为达此目的,推土机采用了其它任何处理器都没有过的模块化设计,整数核心、浮点核心按照2:1的比例组成一个个模块,每个模块既可以相当于传统的两个物理核心,又可协作运行。
从产品家族序列上看,推土机属于AMD Family 15h。这是K8架构之后开始使用的新型序列。在此之前,Family 10h、11h、12h、14h分别代表服务器和桌面版K10、笔记本移动版K10、Llano APU、Bobcat APU,13h则被很自然地跳过去了。
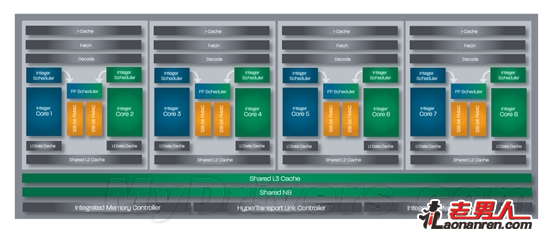
推土机FX处理器架构总图(四模块八核心)

推土机内核照片(四模块八核心)
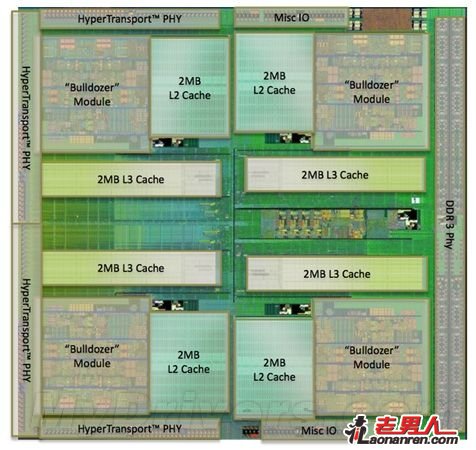
推土机内核结构简图
双核心一模块
在着手设计下一代x86处理器核心的时候,AMD的工程师们认为必须实现核心功耗与面积的优化,而且PC应用的发展也让工程师们必须寻找一条新的路子,能够在不同核心之间实现峰值带宽的最大化,并通过共享模块来充分利用每一平方毫米的核心面积。
最终结果就是能够高效优化资源的双核心模块化。整数管线、一级数据缓存等频繁使用的功能在每个核心里都有单独的功能单元,预取、解码、浮点管线、二级缓存等功能单元则在两个核心里共享使用。这种设计可以让每个核心都能在需要的时候使用更大的、更高性能的功能单元,比每个核心都拥有自己独立的小型功能单元更节省核心面积。
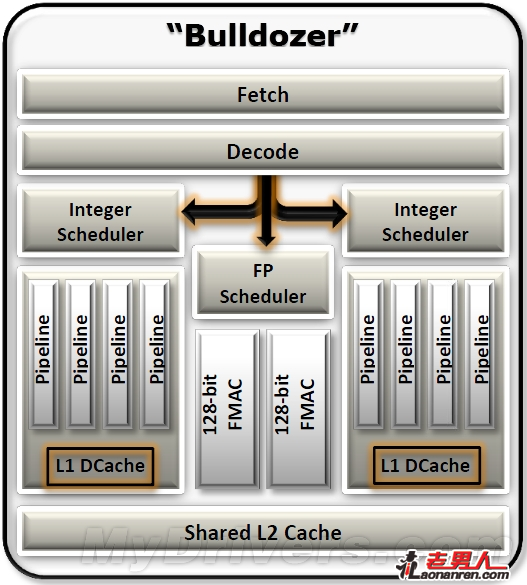
一个推土机模块
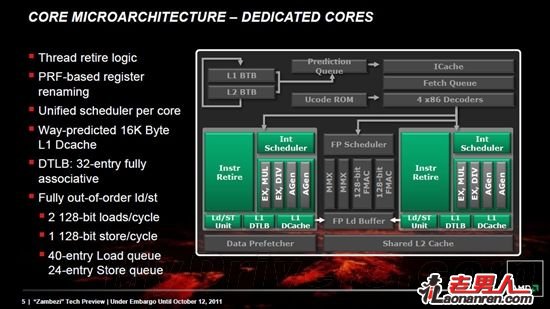
每核心独享的单元
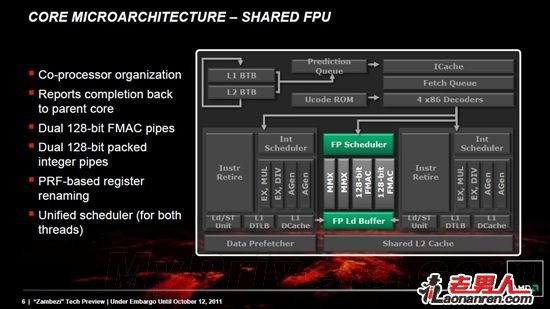
双核心共享浮点单元
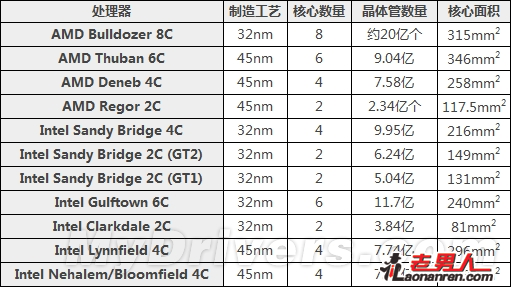
这种设计理念的一个直接体现就是核心面积。八核心推土机是AMD公司历史上制造的最大规模芯片,集成了大约20亿个晶体管,是六核心Phenom II X6、四核心Sandy Bridge的两倍多,但通过功能单元的合理分配,以及32nm SOI新工艺的应用,核心面积被控制在仅仅为315平方毫米,比六核心、45nm工艺的Phenom II X6还要小9%,比四核心、32nm HKMG工艺的Sandy Bridge也只大了46%。















{kind=link}