关于嵌套查询和连接查询的效率问题
2017-10-19
字体:
大中小
浏览:
文章简介:我们来分析方法一的查询过程:先对s和sc做笛卡尔积,得到一个S的行数+SC行数的二维表,然后对二该表进行逐行扫描,本例中也就是对一个9+21
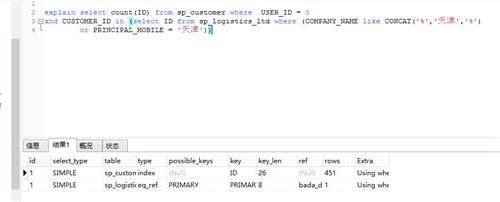
我们来分析方法一的查询过程:先对s和sc做笛卡尔积,得到一个S的行数+SC行数的二维表,然后对二该表进行逐行扫描,本例中也就是对一个9+21 =30 行的表进行扫描。 从查询分析器我们看到,在数据库中的逻辑处理是Inner join ,实际上数据库进行了哈希匹配的操作,在进行这项操作的时候预计成本达到0.

017847(这个cpu成本究竟指什么我还不是很清楚,但可以肯定的是它是个资源消耗指标),预计子树成本为0.0931

SELECT S#,SNAMEFROM S WHERE S# IN (SELECT S# FROM SC WHERE C# = 'C2')

我们来分析方法二的查询过程,数据库先检索选修出课程为C2的学生,得到一个6行的二维表,再对该6行数据和S表进行扫描检索。
从上图可以看出进行物理上的嵌套循环操作,cpu成本仅需要0.00038,执行成本仅需要0.000131,预计子树成本减小到0.0769。
从以上分析可以看出,方法二和方法一同样可以达到检索出选修了课程C2的学生姓名和学号,但是方法二消耗资源要要精减得多,速度要快,成本比方法降低非常多。 因为方法二先进行子结果选择操作,再对子结果进行查询,这样对于时间和空间的开销都要小得多,所以我们可以看到,连接的消耗是很大的。











{kind=link}