汤晓鸥论文 为什么香港中文大学汤晓鸥教授团队的人脸识别技术能够击败人类?
比较幸运的是,已经有这么一个拥有各种不同人脸的标准数据库——Labelled Faces。它拥有超过13,000张不同人脸的图片,它们是从网络上收集的6000个不同的公众人物。更重要的是,每个人都拥有不止一张人脸图片。

当然也存在其他的人脸数据库,但是Labelled faces目前是计算机科学家们所公认的最具参考价值的测试数据集。

面部识别的任务是去比较两张不同的图片,然后判断他们是否是同一个人。

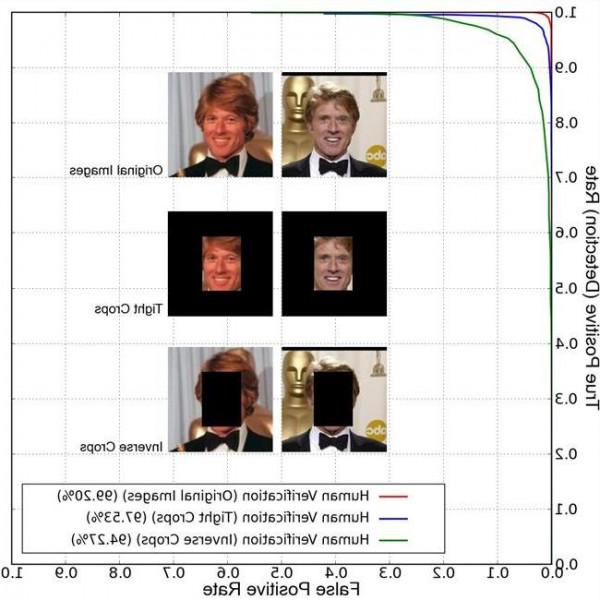
人类在这个数据库上的表现可以达到97.53%的准确度。但是没有任何一个计算机算法能够达到这个成绩。

直到这个新算法的出现。新的算法依照5点图片特征,把每张脸图规格化成一个的像素图,这些特征分别是:两只眼睛、鼻子和嘴角的位置。

然后,算法把每张图片划分成重叠的25*25像素的区域,并用一个数学向量来描述每一个区域的基本特征。做完了这些,就可以比较两张图片的相似度了。

但是首先需要知道的是到底要比较什么。这个时候就需要用到训练数据集了。一般的方法是使用一个独立的数据集来训练算法,然后用同一个数据集中的图片来测试算法。

但是当算法面对训练集中完全不同的两张图片的时候,经常都会识别失败。“当图片的分布发生改变的时候,这种训练方法就一点都不好了。”汤晓鸥教授说到。

相反,他们用四个拥有不同图片的,完全不同的数据集来测试“高斯”算法。举个例子,其中一个数据集是著名的Multi-PIE数据库,它包含了 337个不同的物体,从15种不同的角度,在19种不同的光照情况下,分别拍摄4组图片。另一个数据库叫做Life Photes包含400个不同的人物,每个人物拥有10张图片。

用这些数据库训练了算法后,他们最终让新算法在Labelled Faces数据库上进行测试。目标是去识别出所有匹配和不匹配的图片对。

请记住人类在这个数据库上的表现是97.53%的精确度。“我们的算法已经超过99%的精确度,这也是识别算法第一次击败人类。”汤晓鸥教授说道。
这是一个令人印象深刻的结果,因为数据中的照片包含各种各样不同的情况。
汤晓鸥教授指出,仍然有很多挑战在等着他们。现实情况中,人们可以利用各种附加的线索来识别,比如脖子和肩膀的位置。“超过人类的表现也许只是一个象征性的成就罢了”汤教授说。
另一个问题是花费在训练新算法上的时间,还有算法需要的内存大小以及识别两幅图所需要的时间。这可以用并行计算和特制处理器等技术来加快算法的运行时间。
12.21日,深圳3W咖啡,汤晓鸥教授将现场为你解读人脸识别技术,敬请期待。














![>港中文大学教授卢煜明 赵慧君[香港中文大学教授]](https://pic.bilezu.com/upload/b/d3/bd31097ca87807a4bd4ce0f8fa63c752_thumb.jpg)


{kind=link}